LMCache
Star 8k

The best performance KV caching layer between LLM inference engines and storage backends.
vLLM production stack
Star 2.3k
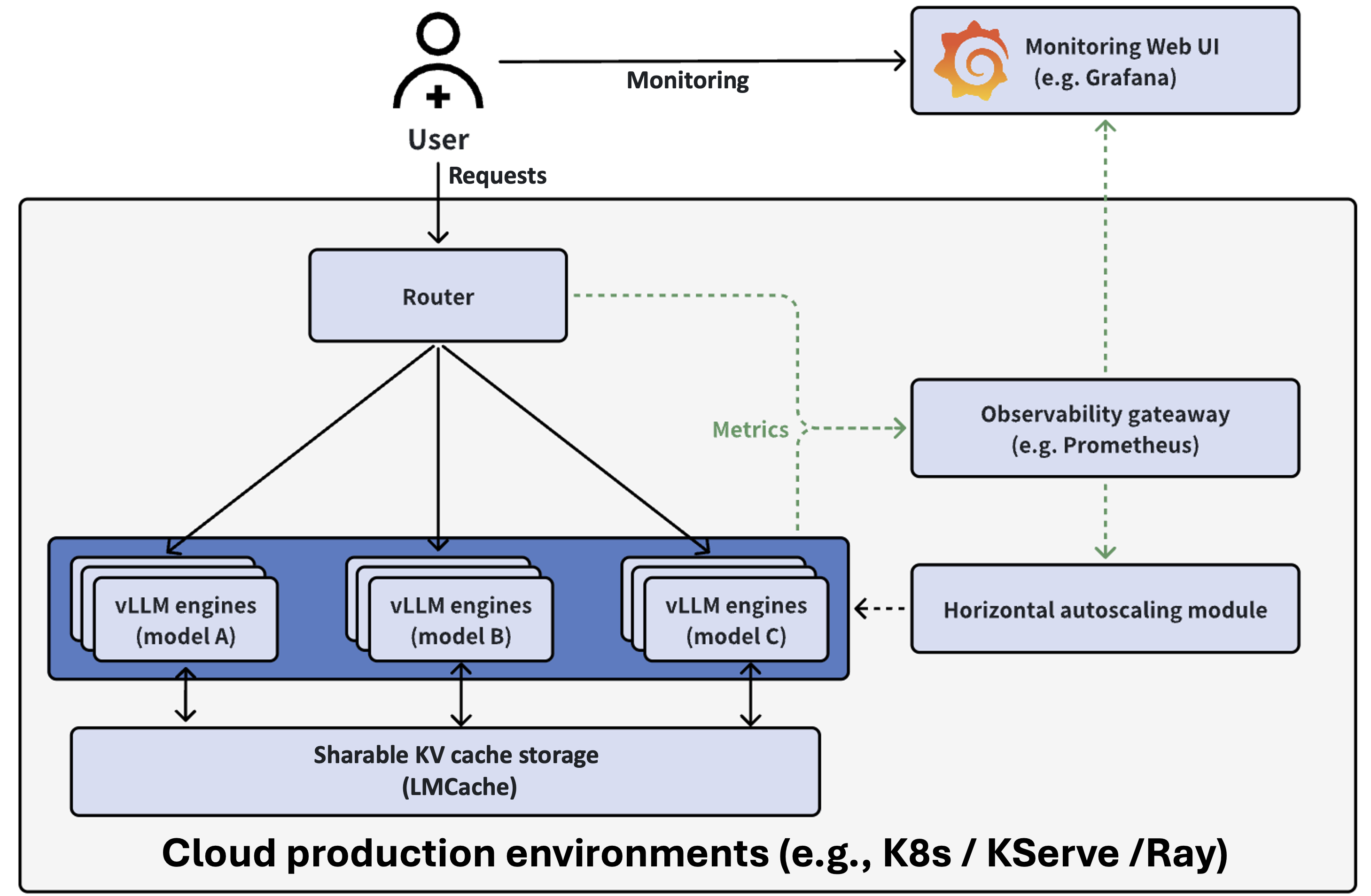
Cluster-wide Kubernetes orchestration.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
arXiv
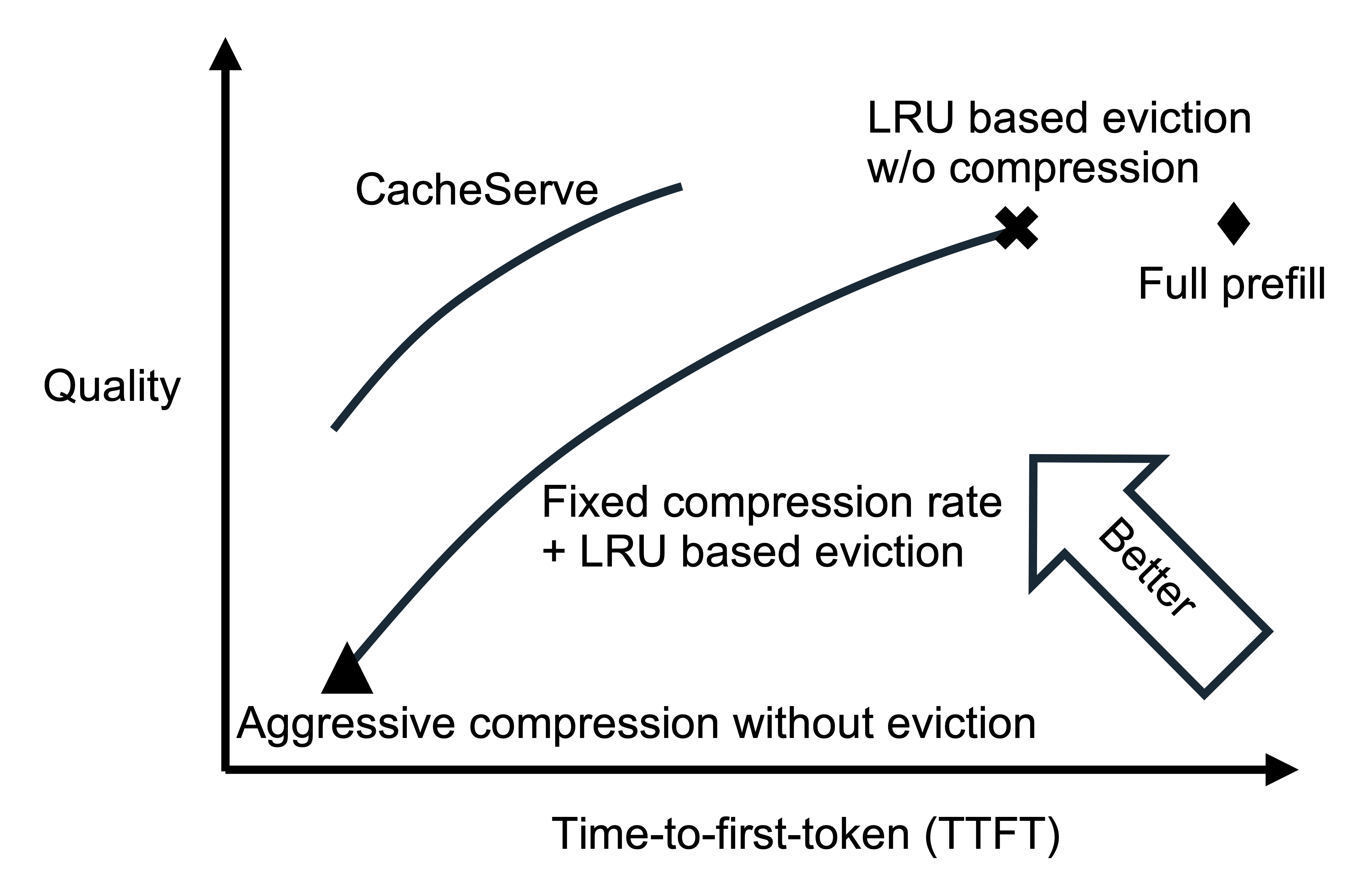
When a storage tier is full, whether we should compress the KV caches more aggressively or evict them to lower storage tiers.
DroidSpeak: KV Cache Sharing for Cross-LLM Communication and Multi-LLM Serving
NSDI’26
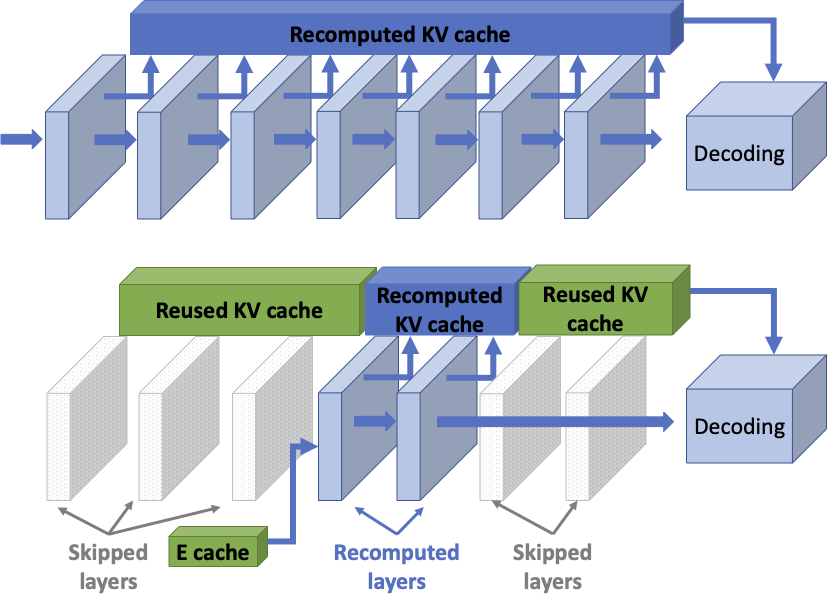
The first distributed LLM inference system that enables KV cache reuse across distributed nodes running inference of different LLMs.
METIS: Fast Quality-Aware RAG Systems with Configuration Adaptation
SOSP’25
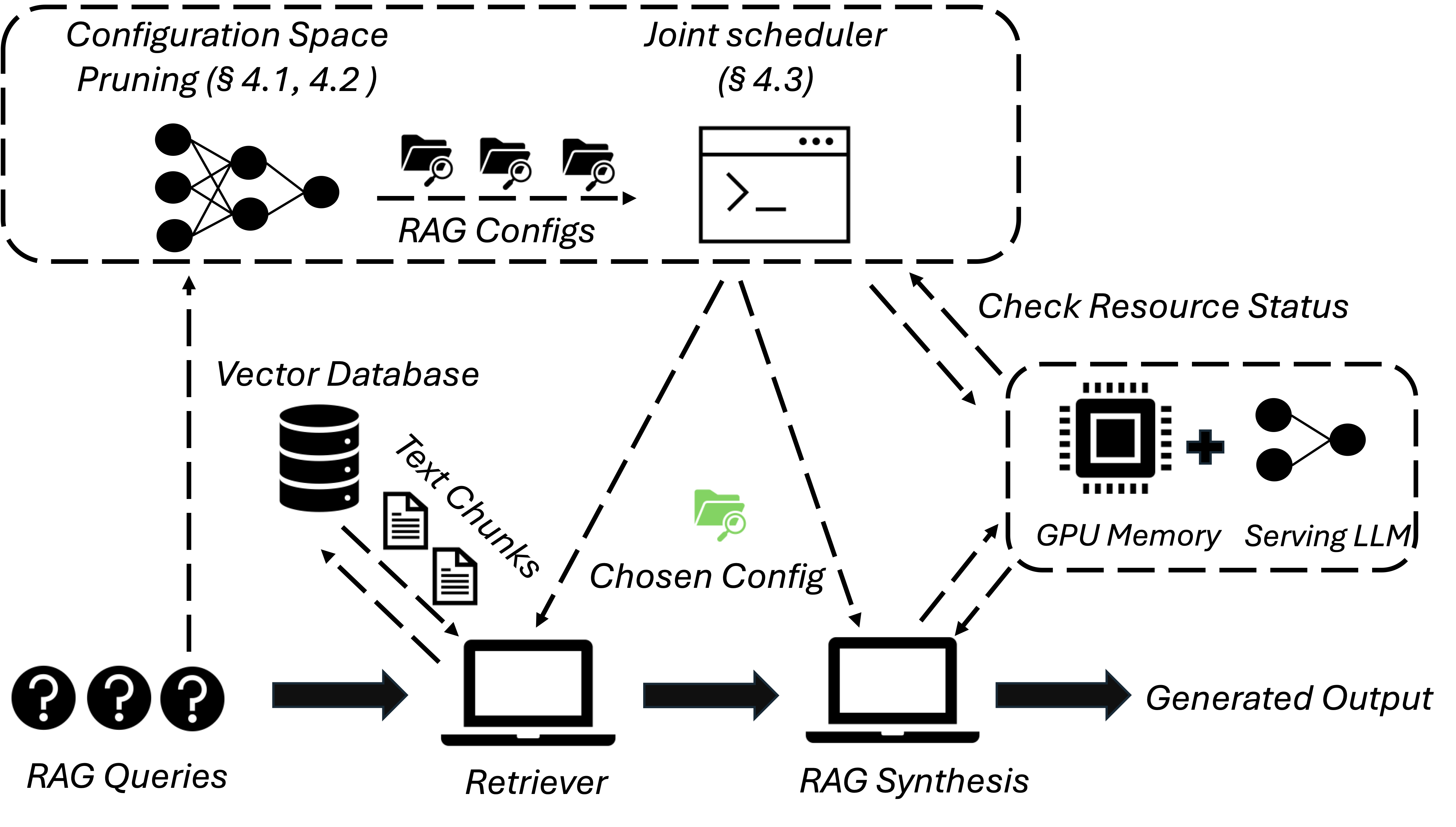
The first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods.
LMBenchmark
Star 55
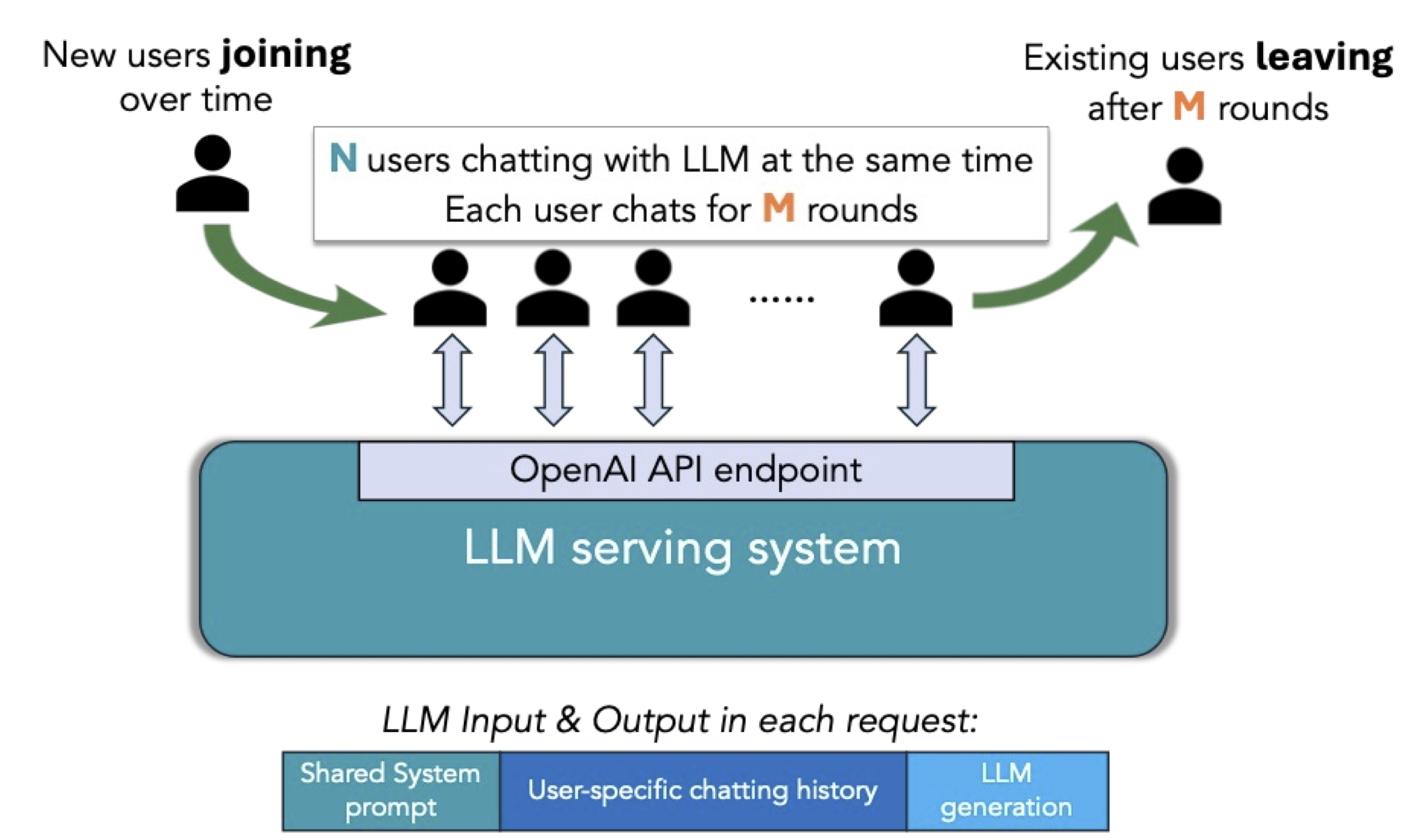
Systematic and comprehensive benchmarks for LLM systems
